




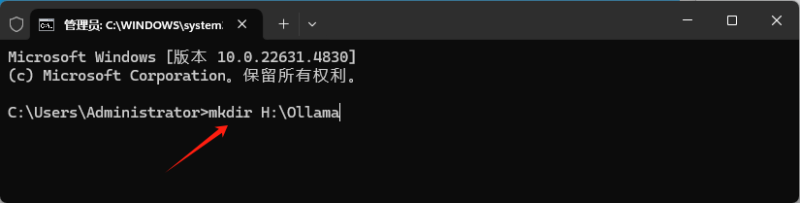
环境准备
- 操作系统:
- 支持 macOS、Linux(推荐 Ubuntu/Debian)或 Windows(需 WSL2)。
- 确保系统已安装最新驱动和依赖库。
- 硬件要求:
- CPU:建议至少 4 核以上。
- 内存:16GB+(7B 模型需 8GB+,13B 模型需 16GB+)。
- GPU(可选):NVIDIA GPU(支持 CUDA)或 AMD GPU(支持 ROCm)可显著加速推理。
- 依赖安装:
- 安装 Docker(可选,用于容器化部署)。
- 确保已安装
curlwget等基础工具。

DeepSeek R1 本地部署相关资料
注意事项
建议使用 NVIDIA 卡,体验会好不少,AMD 显卡未做测试,但应该也是能跑的
欢迎各位在本文档评论区反馈各自运行情况,这样可以帮到更多人
LM Studio
直接下载 ↓ 【Windows 版】
官网下载:https://lmstudio.ai/或者工具包下载
直接下载 ↓ 【macOS 版】
官网下载:https://lmstudio.ai/或者工具包下载
模型列表
请选择文件体积小于自己显存大小的模型,略大一些的虽然也能跑,但是速度会慢很多。因个人能力有限,以下模型推荐不一定是最好的
更多模型下载
链接1:https://www.modelscope.cn/organization/lmstudio-community
记得用搜索功能搜索 DeepSeek 相关模型
链接2:https://www.modelscope.cn/collections/DeepSeek-R1-Distill-GGUF-eec5fee2f2ee42
相比链接1会多一点不同量化精度的模型
点击模型名称可以直接下载
|
显存大小
|
推荐模型
|
备注
|
|---|---|---|
|
32GB
|
||
|
24GB
|
二选一即可,比较推荐第一个
Q5 质量上可能会好一点,但是因为太接近 24G 显存,所以上下文多了之后,速度可能会慢。
上面的 Q6 勉强也能跑,但速度会比较慢。
|
|
|
16GB
|
||
|
12GB
|
||
|
11GB
|
||
|
8GB
|
二选一即可
|
|
|
6GB
|
二选一即可
|
|
|
4GB
|
二选一即可,比较推荐第一个
第二个 4G 显存能跑,但可能会比较慢
|
|
|
3GB、2GB
|
如何查看自己的显存

|
显存大小
|
对应N卡型号
|
|---|---|
|
2GB
|
GTX 1050、GT 1030
|
|
3GB
|
GTX 1060 3GB
|
|
4GB
|
GTX 1050 Ti
|
|
6GB
|
GTX 1060 6GB、RTX 2060 6GB、RTX 3050 (6GB)
|
|
8GB
|
GTX 1080、GTX 1070 Ti、GTX 1070、RTX 2080 SUPER、RTX 2080、RTX 2070 SUPER、RTX 2070、RTX 2060 SUPER、RTX 3070 Ti、RTX 3070、RTX 3060 Ti、RTX 3060 (8GB)、RTX 3050 (8GB)、RTX 4080、RTX 4060 Ti 8GB、RTX 4060、RTX 5070
|
|
11GB
|
|
|
12GB
|
RTX 2060 12GB、RTX 3060 (12GB)、RTX 4070 Ti SUPER、RTX 4070、RTX 5070 Ti
|
|
16GB
|
RTX 4060 Ti 16GB、RTX 5080
|
|
24GB
|
RTX 3090 Ti、RTX 3090、RTX 4090
|
|
32GB
|
RTX 5090
|
DeepSeek API 注册指南
1、DeepSeek API
表格最后修改于2025年2月21日,部分优惠信息可能会有变动,请以实际为准
一般情况,1 个英文字符 ≈ 0.3 个 token,1 个中文字符 ≈ 0.6 个 token
表格中显示的是 R1 模型每百万 tokens 的输入输出价格
|
名称
|
网址
|
优惠活动
|
输入/百万
|
输出/百万
|
备注
|
|---|---|---|---|---|---|
|
DeepSeek 官方
|
送10元额度
|
4元
|
16元
|
现已恢复充值,官方API有硬盘缓存,所以实际成本会略低,点击查看相关文档
|
|
|
火山引擎
|
https://www.volcengine.com/experience/ark?utm_term=202502dsinvite&ac=DSASUQY5&rc=614C9G41
|
15元代金券
(约375万 R1 的 tokens)
+ 50万 tokens
|
4元
|
16元
|
注意:15元代金券需要填写邀请码注册才能获取,可以直接点击左侧的网址注册
15元代金券约可抵扣 375 万 tokens(DeepSeek R1)
代金券有效期 90 天,活动时间: 2025年2月20日0:00 – 2025年3月15日23:59
|
|
派欧算力云
|
送 5000 万 tokens (50 元代金劵)
|
4元
|
16元
|
注意:赠送额度必须通过邀请码注册才有这么多,可填写邀请码MLBDS6,或直接点击前面的网址
|
|
|
硅基流动
|
送14元额度
|
4元
|
16元
|
Pro 版本无法通过赠送的余额调用
|
|
|
阿里云百炼
|
送 1000 万 tokens
|
4元
|
16元
|
注意额度期限,点击查看相关文档
|
|
|
商汤大装置
|
https://console.sensecore.cn/aistudio/
|
免费至5月9日
|
4元
|
16元
|
|
|
讯飞星辰
|
https://training.xfyun.cn/account
|
免费至3月10日
|
4元
|
16元
|
注册方法可以参考之前的这个文档
|
|
华为云
|
送 200 万 tokens
|
注意付费方式和其他的会有所区别,不过一般来说用免费额度就够了
|
|||
|
微软 Azure
|
暂时免费
|
暂时免费
|
注册需要信用卡,暂时没有明确的免费结束日期
|
||
|
NVIDIA NIM
|
1000次免费调用
|
送 1000 次调用
|
企业邮箱注册送5000次调用
|
||
|
腾讯云
|
https://console.cloud.tencent.com/lkeap
|
4元
|
16元
|
价格与官方一致,点击查看相关文档
|
|
|
302.AI
|
4.37元
|
16.74元
|
价格略贵,但模型很全,各家的都有,点击查看相关文档
|
||
|
百度智能云
|
https://console.bce.baidu.com/qianfan/overview
|
2元
|
8元
|
价格为官方的一半,点击查看相关文档
|
|
|
deepinfra
|
5.44 元
|
17.4 元
|
美元价格:$0.75/$2.40 in/out Mtoken
|
||
|
亚马逊 AWS
|
???
|
暂时没弄明白具体要怎么用😢,不过确实是支持的
|
|||
2、现成的APP/网站
|
Flowith
|
部分免费
|
支持联网搜索、知识库,有次数限制,邀请码可以填EKYVYG,多谢大家啦
|
|
|
Monica
|
部分免费
|
支持联网搜索、文档阅读,有次数限制
|
|
|
百宝箱
|
https://tbox.alipay.com/pro
|
暂时免费
|
支持知识库、工作流,所以可以联网搜索,暂时没有额度限制
|
|
腾讯元宝
|
https://yuanbao.tencent.com/
|
暂时免费
|
支持联网搜索,记得手动选择 DeepSeek R1,
|
|
扣子
|
部分免费
|
支持知识库、工作流,所以可以联网搜索,每个用户限制最多 50 条对话/天
|
|
|
Cursor
|
部分免费
|
支持联网搜索、文档阅读,有次数限制,因为原本是AI编程工具,所以处理其它任务不是特别合适
|
|
|
秘塔AI搜索
|
暂时免费
|
需要开启 R1 长思考,主要是做搜索的,不适合聊天,免费指的是搜索和R1免费,上传文档是要收费的
|
|
|
天工AI
|
https://www.tiangong.cn/
|
暂时免费
|
需要开启“深度思考 R1”,主要也是做搜索的,不适合聊天
|
|
钉钉AI助理
|
https://www.dingtalk.com/
|
部分免费
|
需要在钉钉的AI助理中创建基于 DeepSeek 的AI助理来使用
|
|
OpenRouter Free
|
部分免费
|
不保证可用,应该说是经常不可用。也可以通过 API 调用
|
|
|
纳米AI搜索
|
部分免费
|
需要下载 APP 才可以用,部分是收费的,免费版不确定是不是原版 R1
|

© 版权声明
- 本站素材解压密码:
7788 - 本站永久网址:https://mix688.com
- 内容声明:本网站文章部分内容来源于网络,仅供学习参考,如有侵权请联系站长微信ktc909删除处理
- 资源立场声明:本站资源不代表本站立场,不保证内容真实性
- 违法信息处理:禁止发布/转载违法信息,访客发现请向站长举报
- 资源存储声明:资源存储在云盘,链接失效请联系我们更新
THE END






![表情[xiaojiujie]-语义熔炉网](https://www.mix688.com/wp-content/themes/zibll/img/smilies/xiaojiujie.gif)

暂无评论内容